


Regulated industries like healthcare and finance sit on a goldmine of data that could revolutionize patient care, accelerate medical research, optimize operational efficiency, and transform financial services. Yet most of this data remains locked away, trapped behind privacy regulations and compliance requirements. We believe the way most organizations in these sectors handle sensitive data access today is fundamentally broken for the AI-driven, privacy-conscious era.
Hospitals and health systems, for instance, generate petabytes of structured data daily—from electronic health records and claims data to clinical trial results and operational metrics stored in massive healthcare data warehouses. Similarly, financial institutions accumulate vast datasets encompassing customer transactions, credit histories, risk assessments, fraud patterns, and market behaviors. This combined data ecosystem could power breakthrough AI models for drug discovery, predictive analytics for patient outcomes, personalized financial services, fraud detection, and operational insights that save both lives and costs while driving business growth.
But HIPAA compliance, patient privacy concerns, PCI-DSS requirements, GDPR obligations, and the fear of data breaches keep this treasure trove under lock and key. Financial institutions face additional challenges with anti-money laundering (AML) regulations, know-your-customer (KYC) requirements, and fair lending compliance that further restrict data accessibility.
Traditional methods like token-based pseudoanonymization, while well-intentioned, are falling short. Healthcare organizations and financial institutions desperately need realistic data for analytics and AI development but face insurmountable hurdles accessing it due to privacy regulations. A new paradigm is not just coming; it’s required.
Synthetic data offers a powerful, privacy-preserving alternative that unlocks both healthcare and financial data’s potential. Instead of trying to mask or de-identify real patient data or customer financial records—which often leaves them vulnerable to re-identification attacks—synthetic data generation creates entirely artificial datasets that maintain the statistical properties and analytical value of the original data while containing zero actual patient or customer information.
This approach aims to convince you of a few core beliefs:
- Traditional de-identification is often insufficient for robust analytics and AI in regulated industries, and carries residual risk
- Synthetic data represents the future of privacy-preserving analytics across healthcare and finance
- dbTwin represents a leap forward in synthetic data generation—faster, more efficient, and enterprise-ready for healthcare data warehouses and financial data platforms
The Quality-Privacy Balance: How We Measure Success
Before diving into our benchmarking results, it’s crucial to understand how synthetic data performance is measured. Success in synthetic data generation requires balancing two critical dimensions:
Data Quality (Utility): How well does synthetic data preserve the analytical value of the original? High-quality synthetic data should:
- Maintain the same statistical distributions as real data
- Enable machine learning models to perform comparably when trained on synthetic vs. real data
- Preserve correlations and patterns that drive business insights
We measure data utility through three key metrics:
- Distribution Similarity: We compare histograms between real and synthetic data using total variational distance (TVD) averaged over columns. Lower TVD values indicate better fidelity—essentially measuring how closely synthetic data mirrors real data patterns.
- Association Similarity: We compute the similarity of pairwise associations within real and synthetic data—with values close to 1 indicating highly similar feature-interactions in real and synthetic data. For categorical columns, we use Cramer’s corrected statistic. For categorical-numerical columns, we use eta-squared metric. For pure numerical columns, we use cosine similarity.
- ML Performance: We test whether machine learning models trained on synthetic data perform similarly to those trained on real data, using ratio of AUROC (Area Under Receiver Operating Characteristic) with a standard ML-classifier (LightGBM) trained on synthetic data and trained on real-data. In both cases, the classifiers are tested on hold-out data.
dbTwin Outperforms Industry Standards
To demonstrate dbTwin’s capabilities, we conducted comprehensive benchmarking against current industry standards. We tested our technology on 5 diverse datasets representing different types of structured data commonly found in healthcare and finance:
| Adult Census | 48k × 13 | Demographics data including income, education, and employment status – relevant for financial risk assessment and healthcare accessibility analysis |
| Real Census | 149k × 43 | Detailed population demographics data used for market segmentation, insurance underwriting, and public health planning |
| Alarm | 10k x 39 | Synthetic dataset for benchmarking patient monitoring systems containing 37 medical variables related to patient vital signs and conditions |
| Forest Cover | 290k x 56 | Environmental data including soil types and forest characteristics – relevant for environmental risk assessment in insurance and ecological health studies |
| Credit Default (UCI) | 15k x 26 | Credit default prediction dataset containing customer payment histories, demographic factors, and financial behaviors critical for credit risk modeling |
For comparison, we benchmarked against Gretel.ai’s commercially available ACTGAN implementation [1]—currently one of the leading deep learning approaches for synthetic data generation.
The results demonstrate that dbTwin technology delivers superior performance across both healthcare and financial use cases, providing the speed, accuracy, and privacy protection required for enterprise-scale deployment in regulated industries. This breakthrough enables organizations to unlock their data’s transformative potential while maintaining the stringent privacy and compliance standards demanded by modern regulatory frameworks.
Summary of Main Findings
- Superior Data Quality: As shown in Figure 1, both dbTwin variants achieved total variational distance values around 1e-4—orders of magnitude better than competitive solutions. Both dbTwin solutions also achieved association similarity greater than 0.9. This means dbTwin synthetic data maintains near-perfect statistical fidelity to original datasets, preserving the analytical value needed for robust insights.
- Maintained ML Performance: Figure 3 demonstrates that machine learning models trained on dbTwin synthetic data perform comparably to those trained on real data, with AUROC ratios consistently north of 0.95. dbTwin Flagship consistently outperforms Gretel’s ACTGAN and dbTwin Core—specifically on complex data with multi-label targets. This showcases the utility of dbTwin for model development and data-collaboration
- Speed and Efficiency: dbTwin Flagship is 20x faster than current deep learning approaches like CTGAN, TVAE, and Transformers. In healthcare environments where data teams need rapid iteration and enterprise-scale processing, this speed advantage is game-changing.
Key Takeways
These results demonstrate that synthetic data technology has reached a maturity level where it can serve as a true replacement for real healthcare and financial data in most analytical workflows. For healthcare organizations, this breakthrough means:
- Accelerated Innovation: Data teams can access realistic datasets immediately, without waiting months for privacy reviews and de-identification processes.
- Enhanced Collaboration: Synthetic healthcare data can be safely shared with research partners, technology vendors, and analytics teams without HIPAA compliance concerns.
- Reduced Risk: Zero patient information exposure eliminates the risk of data breaches and regulatory violations that plague traditional data sharing.
- Enterprise Scale: dbTwin’s 20x speed advantage makes it feasible to generate synthetic versions of massive healthcare data warehouses, enabling organization-wide analytics democratization.
The shackles of legacy data access are breaking. Traditional de-identification methods that leave healthcare organizations vulnerable while limiting analytical capabilities are becoming obsolete. dbTwin represents the next evolution in enterprise synthetic data generation: faster, more accurate, and ready to revolutionize how healthcare organizations harness their most valuable asset—their data.
[1] Xu, L., Skoularidou, M., Cuesta-Infante, A., & Veeramachaneni, K. (2019). Modeling tabular data using conditional gan. Advances in neural information processing systems, 32.
[2] https://github.com/gretelai/gretel-synthetics/tree/master
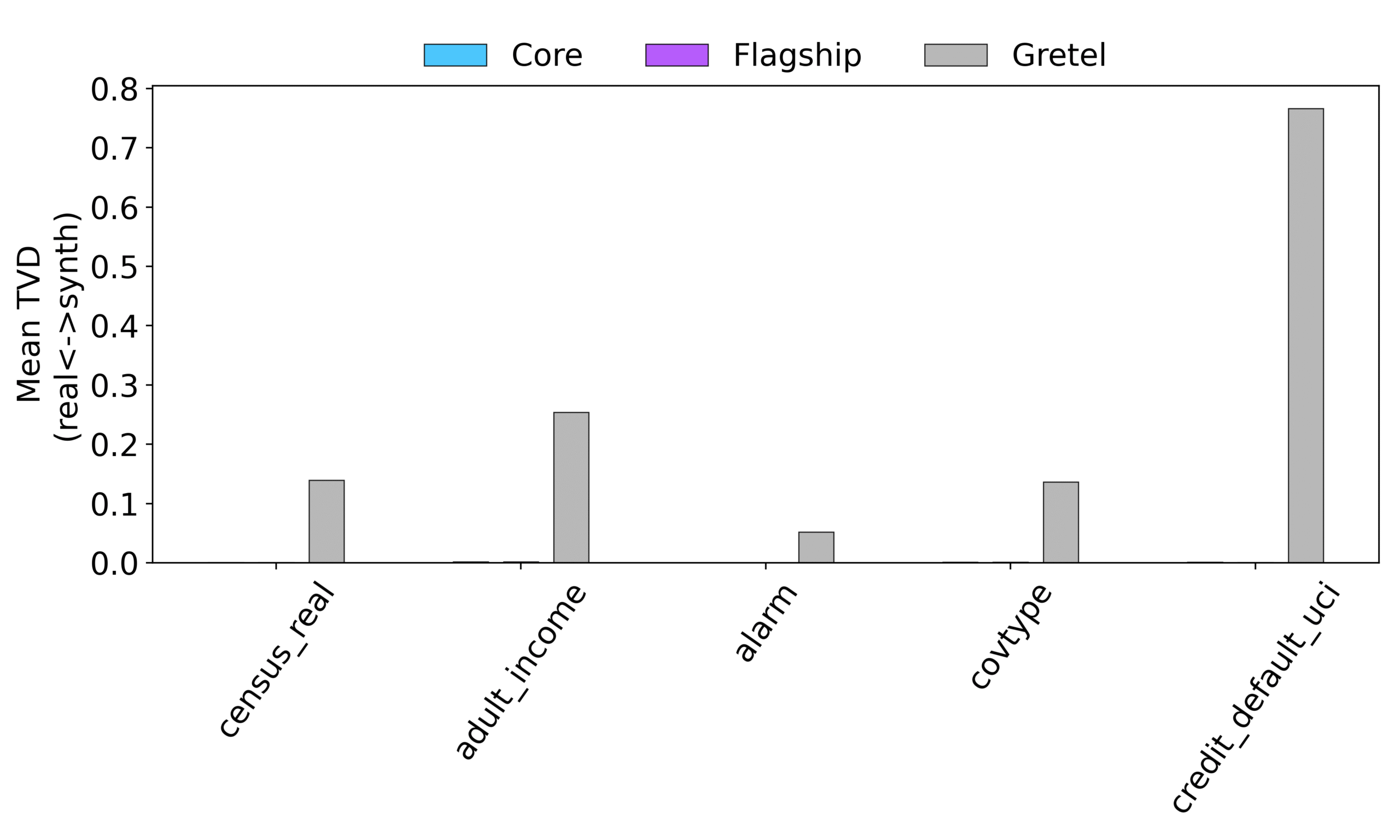
Figure 1: Total-variational distance (overaged over all columns) for dbTwin Core, dbTwin Flagship and Gretel averaged over all columns. dbTwin Core and Flagship have very low TVD values ~ 1e-4 (denoting greater fidelity between real and synthetic histograms).
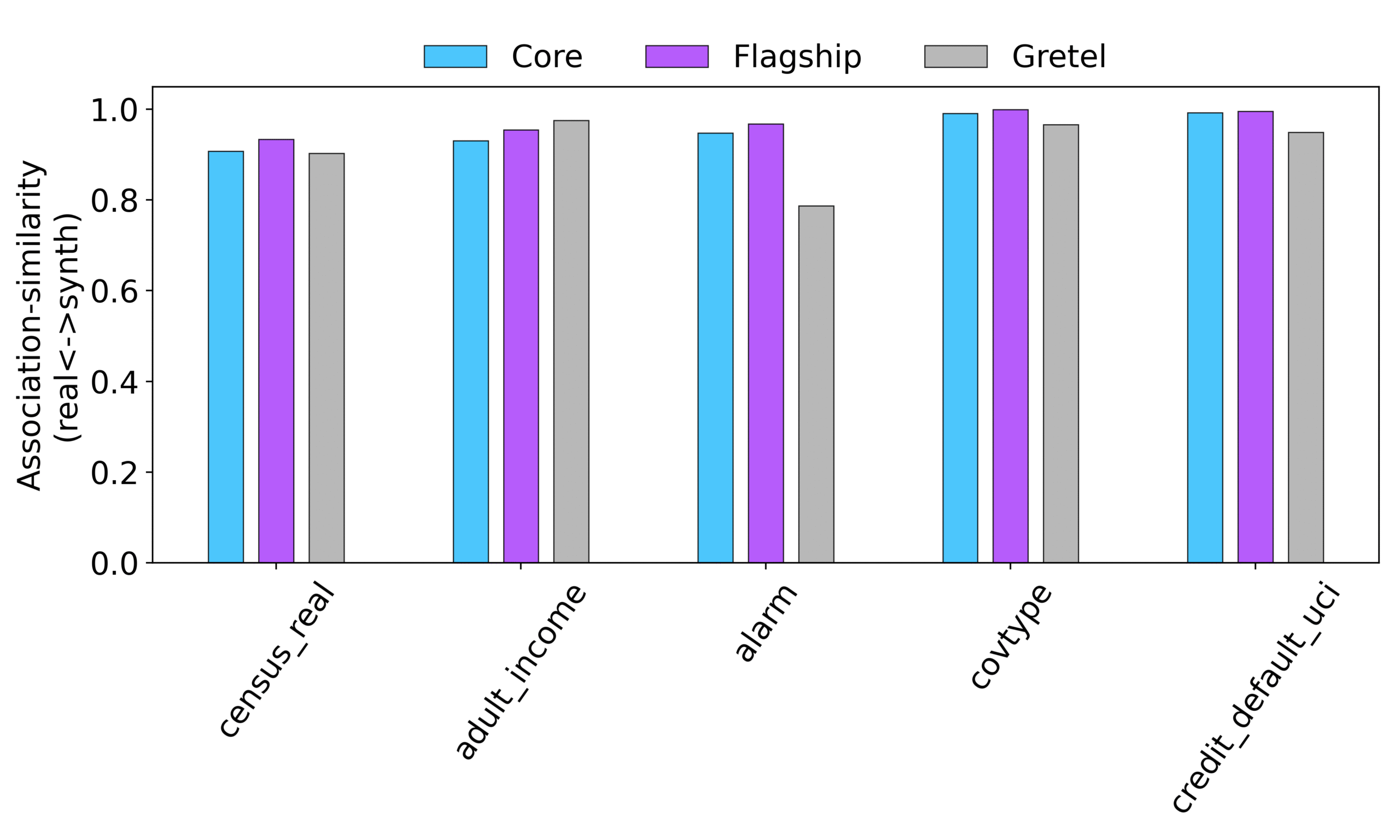
Figure 2: Similarity of pairwise associations within real and synthetic data—with values close to 1 indicating highly similar feature-interactions in real and synthetic data.
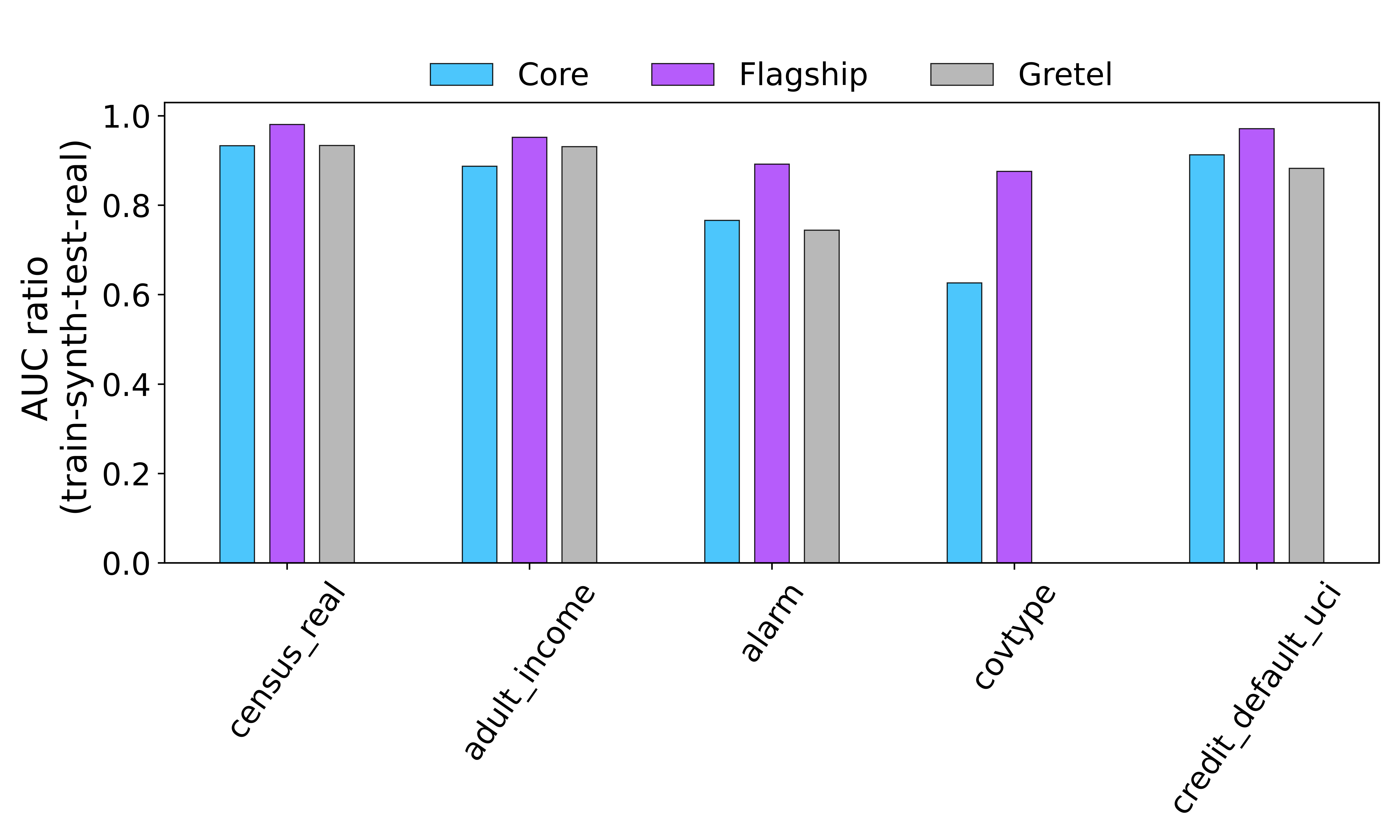
Figure 3: ML performance as measured by AUROC ratio on Train-synthetic-test-real paradigm using LightGBM Classifier. For ‘covtype’ data, Gretel’s synthetic data did not converge because of missing labels in the target column.
